hello,
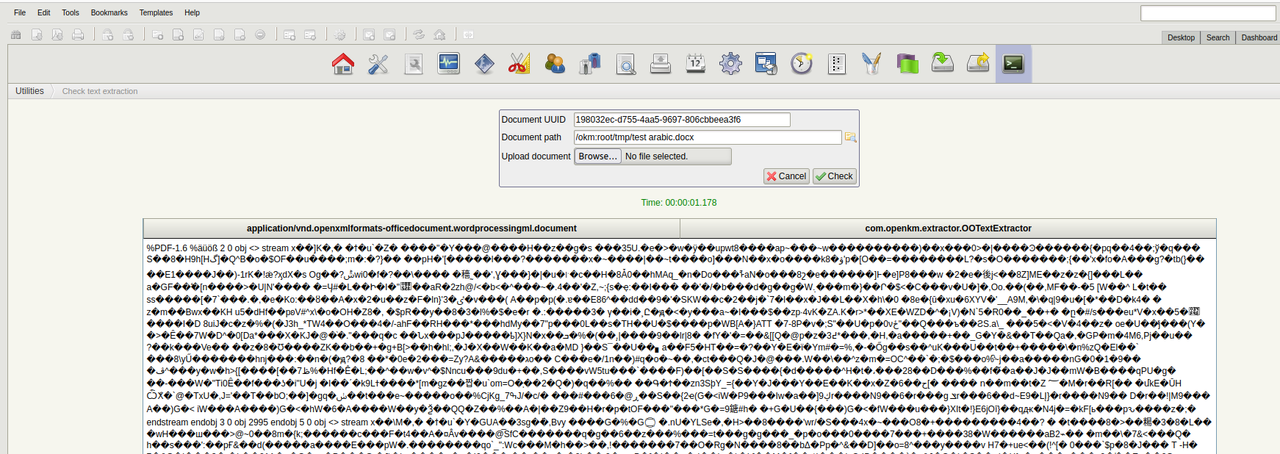
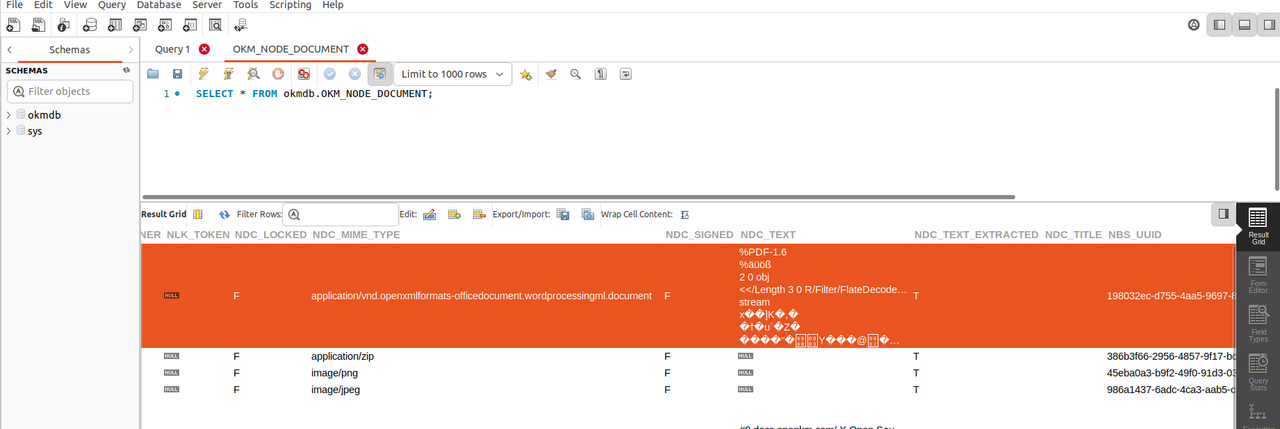
when I extract docx document I m getting un-readable content
please see the attachments , and when i search the content of the document ,nothing is showing
when I extract docx document I m getting un-readable content
please see the attachments , and when i search the content of the document ,nothing is showing
Attachments
(11.54 KiB) Downloaded 1107 times






{kind=link}