Hello Community,
I've getting in trouble with my openKM installation since few days after the installation.
----
My first problem is, that on my latest version of Community Edition openKM (6.3.12 (build: a3587ce)) there is no OCR working for uploaded and existing files.
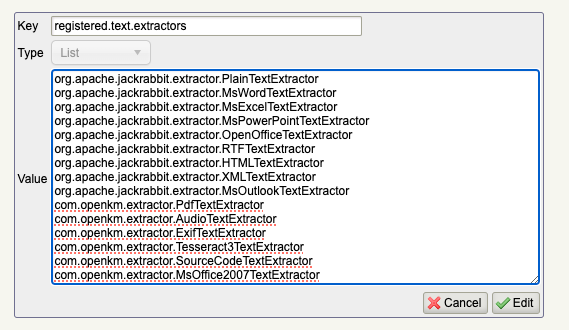
I've already configured and installed ocr like this:
----
My second problem is, that the full text search are not working for documents which already have ocr before uploading. So when I try to find a document with a specific word from a pdf file, I can't find this with the search.
Thanks for your assistance and best regards
Toorms
I've getting in trouble with my openKM installation since few days after the installation.
----
My first problem is, that on my latest version of Community Edition openKM (6.3.12 (build: a3587ce)) there is no OCR working for uploaded and existing files.
I've already configured and installed ocr like this:
Code: Select all
When I testing a documents with sql request like this:
system.ocr = /usr/bin/tesseract ${fileIn} ${fileOut}
system.ocr.rotate = 90;180;270;
system.pdf.force.ocr = True Code: Select all
I've got 0 rows return. select * from OKM_NODE_DOCUMENT WHERE NBS_UUID='id from doc which should be ocr';----
My second problem is, that the full text search are not working for documents which already have ocr before uploading. So when I try to find a document with a specific word from a pdf file, I can't find this with the search.
Thanks for your assistance and best regards
Toorms