Hello guys.
Now i has millions of license files (text format, but name with .lic suffix), each license file includes one serial number. please review attached file:
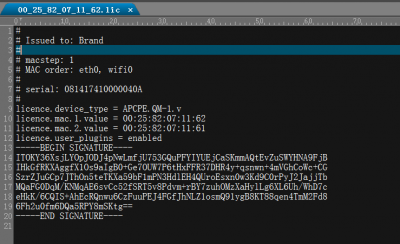 license.png (17.2 KiB) Viewed 5668 times
I want to uploads theses licenses to server , then some one can download then by searching the file name or series number.
license.png (17.2 KiB) Viewed 5668 times
I want to uploads theses licenses to server , then some one can download then by searching the file name or series number.
After uploading the license, i can find the by searching the file name but cannot find it by searching the serial number .
I check the log, the extractor seems that identify the file MIME type as 'application/octet-stream' , even i added the 'lic' to the extensions:
 added_lic_extension.png (4.67 KiB) Viewed 5668 times
, the extractor still didnot work correctly.
added_lic_extension.png (4.67 KiB) Viewed 5668 times
, the extractor still didnot work correctly.
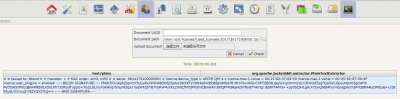 check_extraction.png (34.18 KiB) Viewed 5668 times
My questions:
check_extraction.png (34.18 KiB) Viewed 5668 times
My questions:
1. Can you tell me to how to fix the MIME type to 'application/plain' for these files?
2. There are millions of the license files named with MAC, each file includes one serial number. Some one somethings search them by serial number, so i want to enable the full text index, but if done , it will take up a lot of space in the database. For my case, can you give me sugguestions?
Thanks.
Now i has millions of license files (text format, but name with .lic suffix), each license file includes one serial number. please review attached file:
After uploading the license, i can find the by searching the file name but cannot find it by searching the serial number .
I check the log, the extractor seems that identify the file MIME type as 'application/octet-stream' , even i added the 'lic' to the extensions:
Code: Select all
But the utility tool - check text extraction works:
2017-11-29 11:47:25,942 [http-bio-0.0.0.0-8181-exec-1] WARN com.openkm.dao.NodeDocumentDAO- There was a problem extracting text from '/okm:root/licenses/Used_licenses/2017/20171009/00:25:82:07:11:02.lic': Full text indexing of 'application/octet-stream' is not supported
2017-11-29 11:47:25,958 [http-bio-0.0.0.0-8181-exec-1] INFO com.openkm.extractor.TextExtractorWorker- processSerial.Working on {docUuid=bf61988e-9b6d-450b-8b0c-5bc321602733, docPath=/okm:root/licenses/Used_licenses/2017/20171009/00:25:82:07:0B:DA.lic, docVerUuid=d271f150-2170-4050-8ba7-0f8a9d5c88cf, date=Tue Nov 28 15:56:32 HKT 2017}
2017-11-29 11:47:25,959 [http-bio-0.0.0.0-8181-exec-1] WARN com.openkm.extractor.RegisteredExtractors- Text extraction failure: Full text indexing of 'application/octet-stream' is not supported
2017-11-29 11:47:25,959 [http-bio-0.0.0.0-8181-exec-1] WARN com.openkm.dao.NodeDocumentDAO- There was a problem extracting text from '/okm:root/licenses/Used_licenses/2017/20171009/00:25:82:07:0B:DA.lic': Full text indexing of 'application/octet-stream' is not supported1. Can you tell me to how to fix the MIME type to 'application/plain' for these files?
2. There are millions of the license files named with MAC, each file includes one serial number. Some one somethings search them by serial number, so i want to enable the full text index, but if done , it will take up a lot of space in the database. For my case, can you give me sugguestions?
Thanks.

